
minGRU选读

minGRU选读
落雨杉minGRU 来源
minGRU 来源于 10/2/2024 Mila
等人提出的Were RNNs All We Needed?一文,下面来浅要阅读和总结一下主要内容也分析一下源码。
Were RNNs All We Needed?
这个“Were”有一点点搞。大有一种江山已逝的美感。
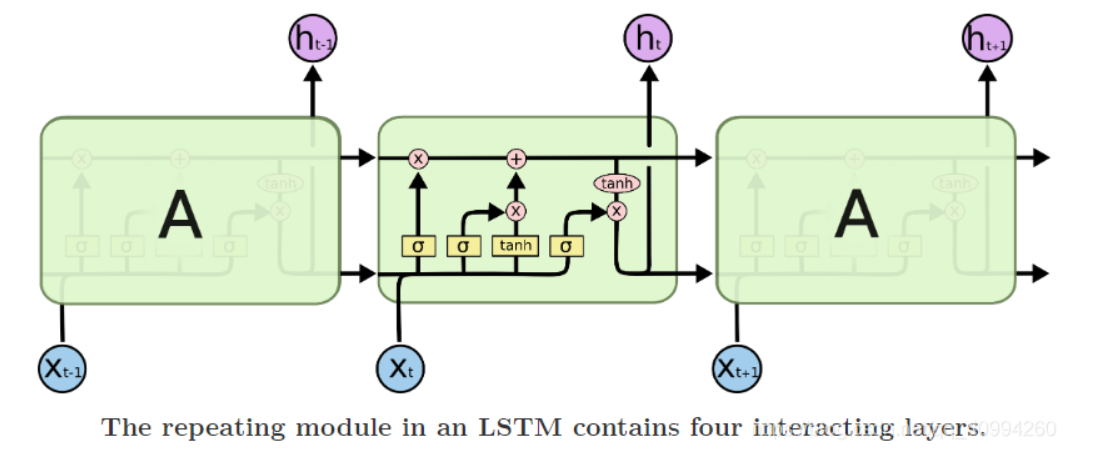
LSTMs 回顾: 长短期记忆网络(Long Short-Term Memory, LSTM)是一种特殊的循环神经网络(RNN),能够学习长期依赖关系。LSTM 通过引入门控机制来解决传统 RNN 中的梯度消失和梯度爆炸问题。LSTM 的核心是其细胞状态(Cell State),它通过一系列门控单元来控制信息的流动。LSTM 分为 4 层:
Forget: 遗忘层,使用一个 sigmoid(决定遗忘值) 遗忘层的作用是决定哪些信息需要从细胞状态中遗忘。通过一个 sigmoid 函数,输出一个 0 到 1 之间的值,表示需要遗忘的信息比例。
其中,
是遗忘门的输出, 和 分别是权重矩阵和偏置向量, 是前一时刻的隐藏状态, 是当前输入。 Store: 存储层,一个 sigmoid(决定更新值),一个 tanh(向量生成) 存储层的作用是决定哪些新的信息需要存储到细胞状态中。首先通过一个 sigmoid 函数决定需要更新的信息比例,然后通过一个 tanh 函数生成新的候选细胞状态。
其中,
是输入门的输出, 是新的候选细胞状态。 Update: 更新层,从
-> ,forget 一个逐元素乘积,store 一个逐元素乘积后与上述加和 更新层的作用是更新细胞状态。通过遗忘门的输出 和前一时刻的细胞状态 逐元素相乘,表示需要保留的旧信息;通过输入门的输出 和新的候选细胞状态 逐元素相乘,表示需要添加的新信息。两者相加得到新的细胞状态 。 Output: 输出层,可以理解为过滤器,运行一个 Sigmoid Layer,决定输出哪一部分的 Cell State。
输出层的作用是决定当前时刻的隐藏状态
。首先通过一个 sigmoid 函数决定需要输出的信息比例,然后通过一个 tanh 函数将细胞状态规范到 -1 到 1 之间,并与 sigmoid 函数的输出逐元素相乘,得到最终的隐藏状态。 其中,
是输出门的输出, 是当前时刻的隐藏状态。 
GRU 回顾:
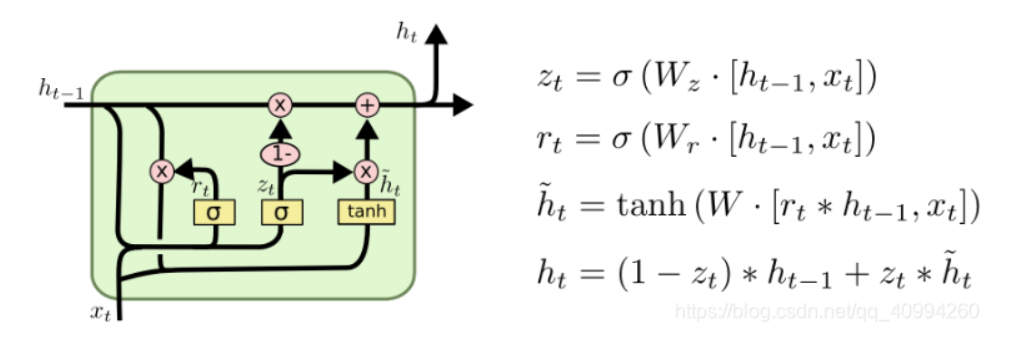
一种引人注目的 LSTMs 变体被称为 GRU,它结合了 Forget Gates 和 Input Gates 到一个单独的 Update Gate,同时,也合并了 Cell State 和 Hidden State,并做出了其他的一些改变。
另外,GRU 比标准 LSTM 更加简洁。
GRU 结构如下:
更新门(Update Gate):
重置门(Reset Gate):
候选隐状态(Candidate Hidden State):
最终隐状态(Final Hidden State):
其中,
表示 sigmoid 函数, 表示 tanh 函数, 表示逐元素乘法, 、 和 是权重矩阵, 是当前时间步的隐状态, 是前一时间步的隐状态, 是当前时间步的输入。
理解时间反向传播(BPTT)
BPTT 即为 BP through time.
作为十多年前的传统 RNN,LSTM 和 GRU 只能按顺序计算,并需要在训练过程中通过时间反向传播 (BPTT)。因此,LSTM 和 GRU 的速度太慢,无法扩展到几百个代币以上的规模,因此已被淘汰。
minGRU 如何巧妙的避免时间维度上的 BP
Revisiting these models, we show that by removing hidden state dependencies from their input, forget, and update gates, LSTMs and GRUs no longer need to BPTT and can be trained efficiently using the parallel scan algorithm. 重新审视这些模型后,我们发现,通过从输入、遗忘和更新门中移除隐藏状态依赖性,LSTM 和 GRU 不再需要 BPTT,而且可以使用并行扫描算法进行高效训练。
Parallel Scan
Blelloch 并行扫描算法
Blelloch 并行扫描算法是一种高效的并行前缀和算法(parallel prefix sum),它用于在并行计算环境中计算前缀和,同时在处理大规模数据时表现出良好的并行性能。为了理解这算法,先简单回顾一下前缀和的概念,然后逐步分析 Blelloch 并行扫描算法的工作原理。
前缀和(Prefix Sum)
前缀和是给定一个数组,计算每个元素的累积和。给定输入数组
A = [a_1, a_2, ..., a_n],其前缀和数组S = [s_1, s_2, ..., s_n]定义如下:s_1 = a_1s_2 = a_1 + a_2s_3 = a_1 + a_2 + a_3- ...
s_n = a_1 + a_2 + ... + a_n
通常,前缀和有两种形式:
- 包含自身的前缀和:
S[i] = A[1] + A[2] + ... + A[i] - 不包含自身的前缀和:
S[i] = A[1] + A[2] + ... + A[i-1],即 exclusive scan。
并行计算的挑战
在串行计算中,前缀和很容易通过线性扫描的方式实现,时间复杂度为 (O(n))。但是,在并行计算中,如果直接顺序计算前缀和,会引入依赖关系,即计算下一个元素时依赖于之前元素的结果,这阻碍了并行化。因此,需要设计特殊的算法来消除这些依赖关系。
Blelloch 并行扫描算法的思想
Blelloch 并行扫描算法通过两次阶段性操作(向上阶段(up-sweep)和向下阶段(down-sweep))实现了前缀和的并行化。这个算法的核心思想是将整个问题分解成两步,每步都是并行操作。
- 向上阶段(up-sweep / reduce phase) 在向上阶段,算法类似于归并操作,将数组元素从下到上累积,通过分组计算来消除数据之间的依赖性。它的目标是通过二叉树结构的方式逐层进行部分和的计算。
- 操作:从底层的元素开始,依次合并相邻元素,形成二叉树结构。
- 每一轮中,相邻元素会被加到一起,并放到更高层的节点位置,形成一个树形结构。最终,这个阶段会在根节点获得整个数组的总和。
- 向下阶段(down-sweep phase)
在获得整个数组的总和后,进入向下阶段。这个阶段的目标是计算前缀和。该过程使用向上阶段的部分和的结果,通过从根节点向下传播和交换信息,最终计算出每个位置的前缀和。
- 操作:通过向下遍历二叉树,将部分和分配到下层节点。
- 具体做法是:将根节点的值重置为零,然后逐层向下传播累积和,在每个子节点处,父节点的值和当前子节点的值一起决定子节点的前缀和。
通过这两步操作,算法将前缀和分配到了所有的叶节点上,从而得到最终的前缀和数组。
算法的并行性
Blelloch 算法的设计很好地利用了并行化:
- 在向上阶段,每一层的节点计算可以并行进行,因为每个节点只依赖于它的两个子节点的值。
- 在向下阶段,类似地,每层的节点可以同时计算,从而得到前缀和的分配。
由于这些操作是在树的层级结构上进行的,而树的高度为 (O(n)),因此每一阶段的复杂度都是 (O(n))。在一个完美的并行计算环境中,整个算法的并行时间复杂度为 (O(n)),显著提高了计算大规模数据的效率。
小结
Blelloch 并行扫描算法通过两个阶段(向上阶段和向下阶段)实现了并行前缀和的高效计算。
向上阶段累积部分和并构建二叉树,向下阶段通过传播和交换信息来计算每个位置的前缀和。
这种算法特别适合在 GPU、多核 CPU 等并行计算环境下处理大规模数据,且时间复杂度为 (O(n)),比顺序计算的线性复杂度更适合并行化任务。
实现
- minGRU:
1 | # https://github.com/lucidrains/minGRU-pytorch/tree/main/minGRU_pytorch |
Reference
- minGRU PyTorch Implementation
- CSDN Blog on RNNs
- [Zhihu Column on RNNs](https://zhuanlan.zhihu.com/p/61472450#:~:text=%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%20(Re)






